這次要來分享的是由 Google 提出用於語義分割任務上的深度學習模型 — DeepLab,
這個 DeepLab 模型隨著時間推移,有推出了採用不同機制的不同版本,到目前總共有四個版本,分別是 DeepLabv1、DeepLabv2、DeepLabv3 和 DeepLabv3+,每個版本都加入了新的機制,不斷提升了語義分割的效能,那今天會先來對 DeepLab 的架構進行分享 
將深度卷積神經網路(Deep Convolutional Neural Network,DCNN)跟條件隨機場(conditional random field,CRF)做結合的一個分割模型,核心特點是使用了一個新的技術:空洞卷積(Dilated Convolution/Atrous Convolution)
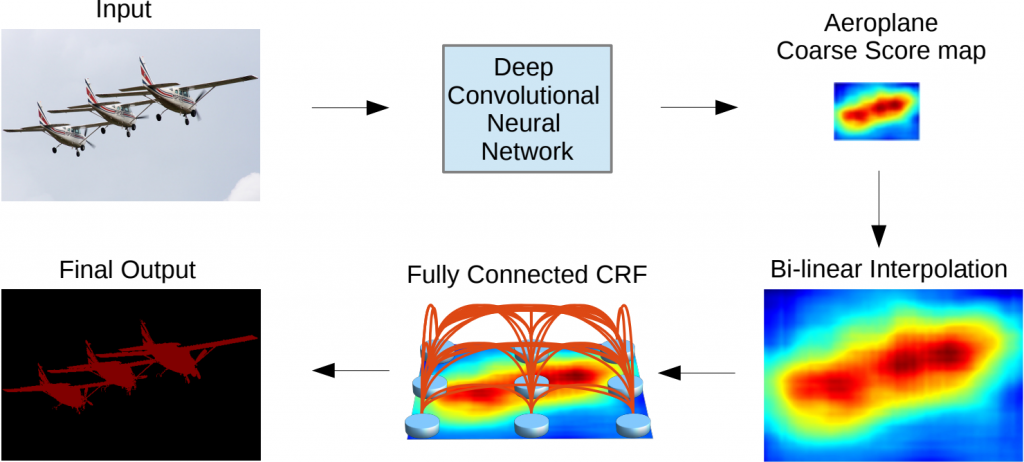
具體來說,就是影像首先會經過一個使用 dilated convolution 的 DCNN,這個過程會解決深度特徵提取器空間分辨率降低的問題,然後,再做雙線性插值,以確保輸出的分割圖與原始影像具有相同的尺寸,最後,為了進一步優化邊緣,DeepLab 使用全連接的 CRF 對結果進行微調,最終將預測進行輸出
是一種特殊的卷積操作,空洞卷積會有個 dilation rate,來調整卷積核之間的間隔大小,從而擴大卷積核的感受野。舉個例子,假設使用一個 3x3 大小的卷積核,步長為 1,並將 dilation rate 設為 2 的空洞卷積進行操作時,這個卷積核的感受野將會變為 5x5(如下圖所示),但如果使用的是一般的卷積進行操作的話,感受野大小會是 3x3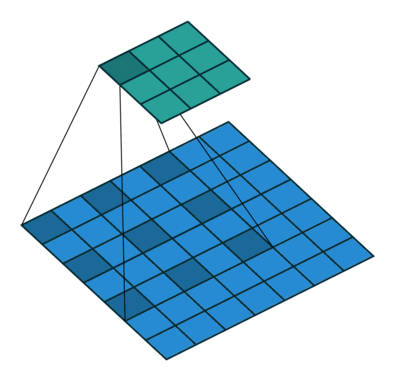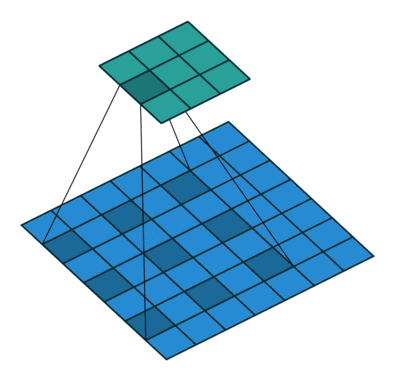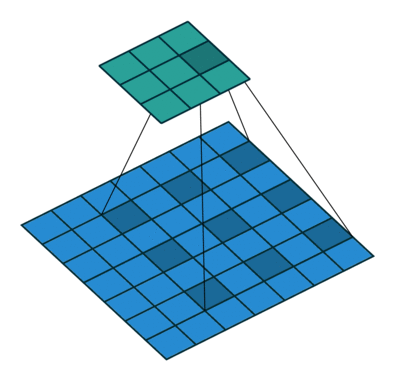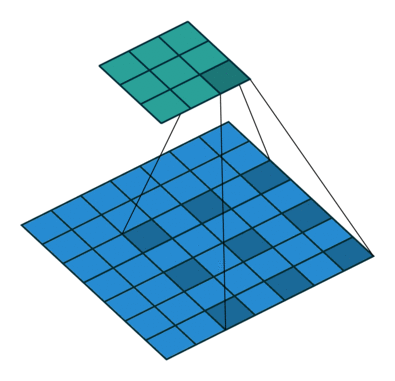
也就是說,空洞卷積可以擴大模型對影像的感知範圍,但卻不會讓影像分辨率下降,這會相當於增強了模型對於影像局部細節的感知能力。(傳統的深度神經網路為了要擴大感受野,往往會需要進行下採樣的操作,但這樣會導致影像的空間分辨率下降,進而影響分割的準確性)
SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS

